致力打造国内好用的AI产品导航平台

开发者:阿里巴巴集团智能计算研究院
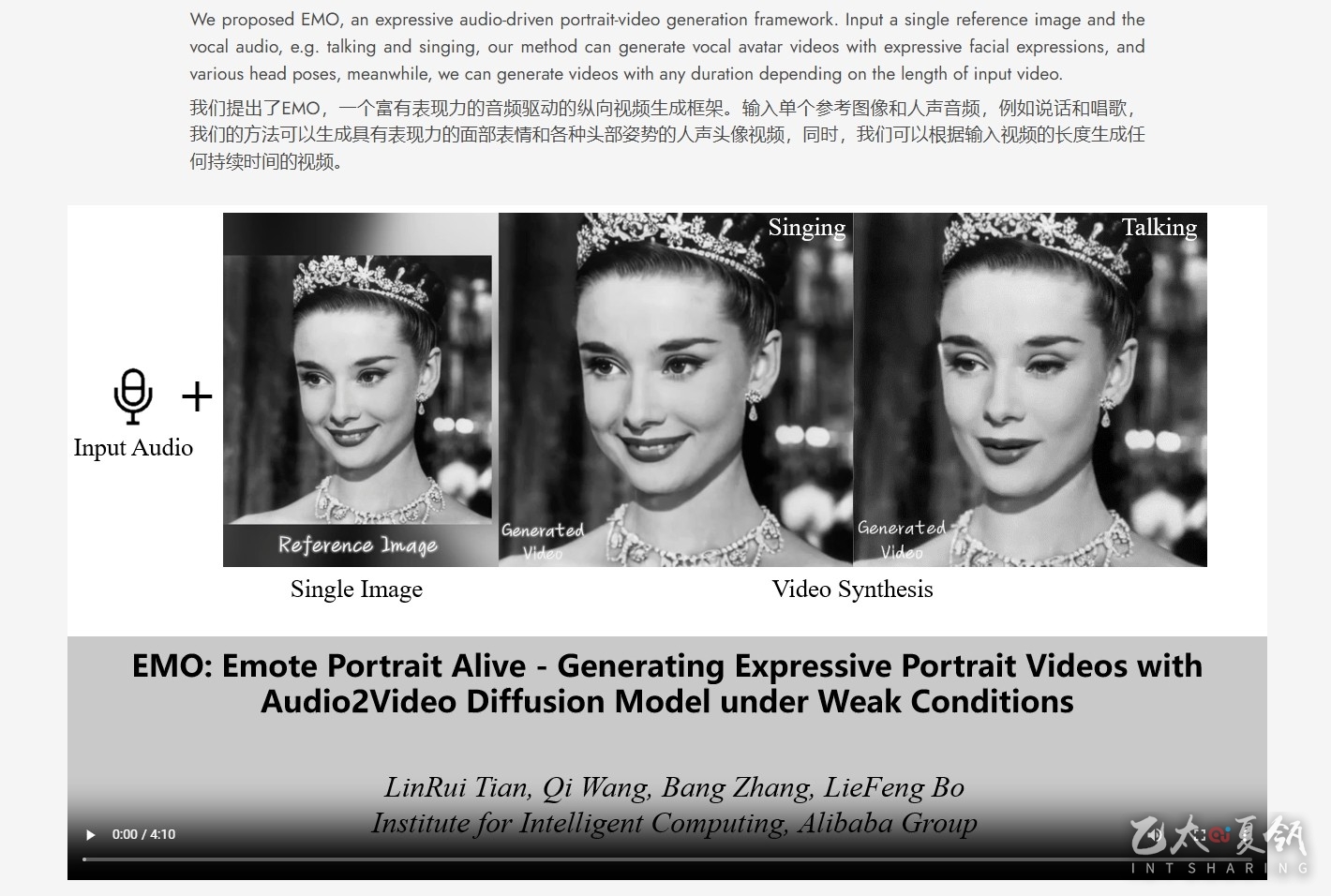
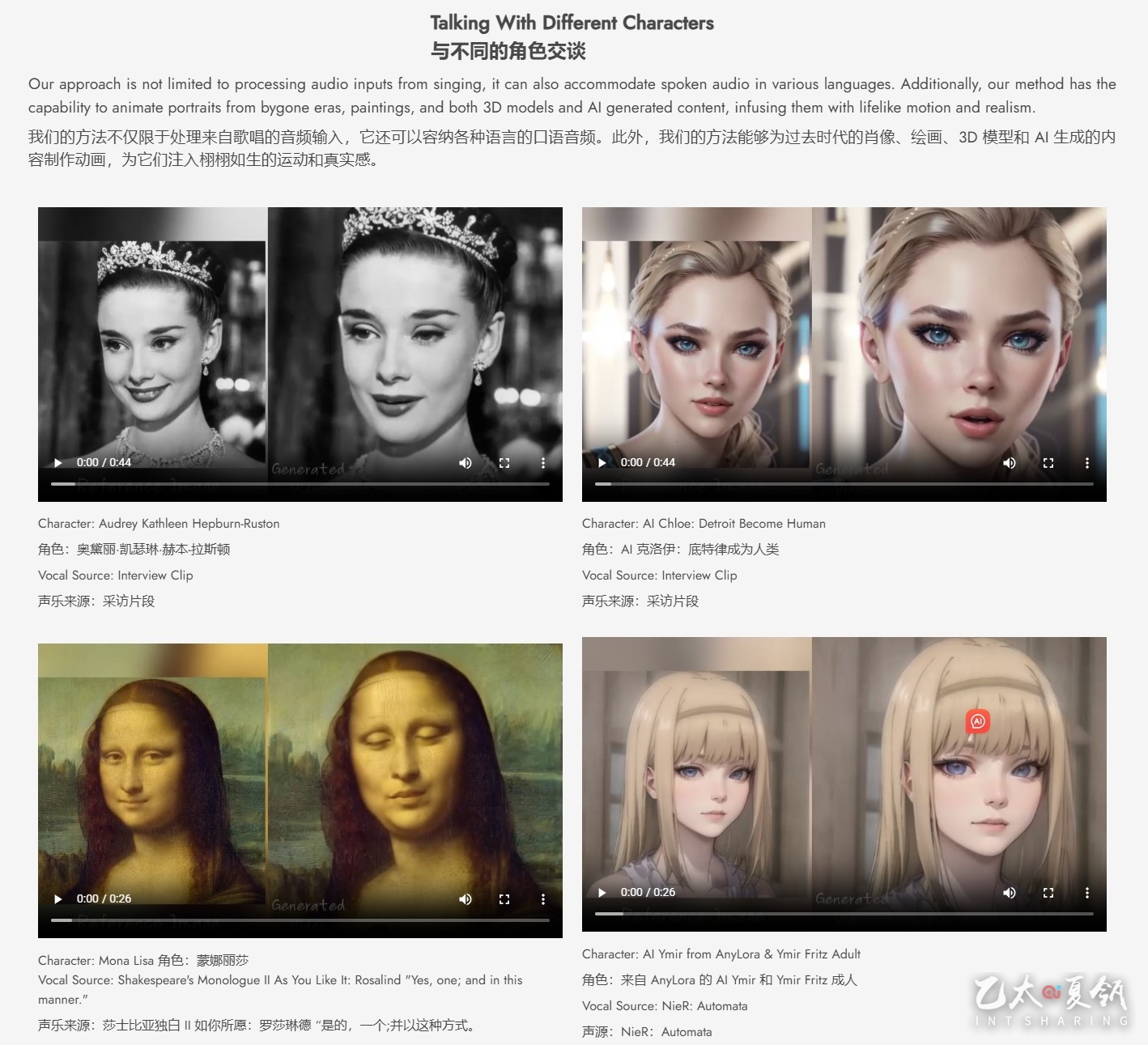
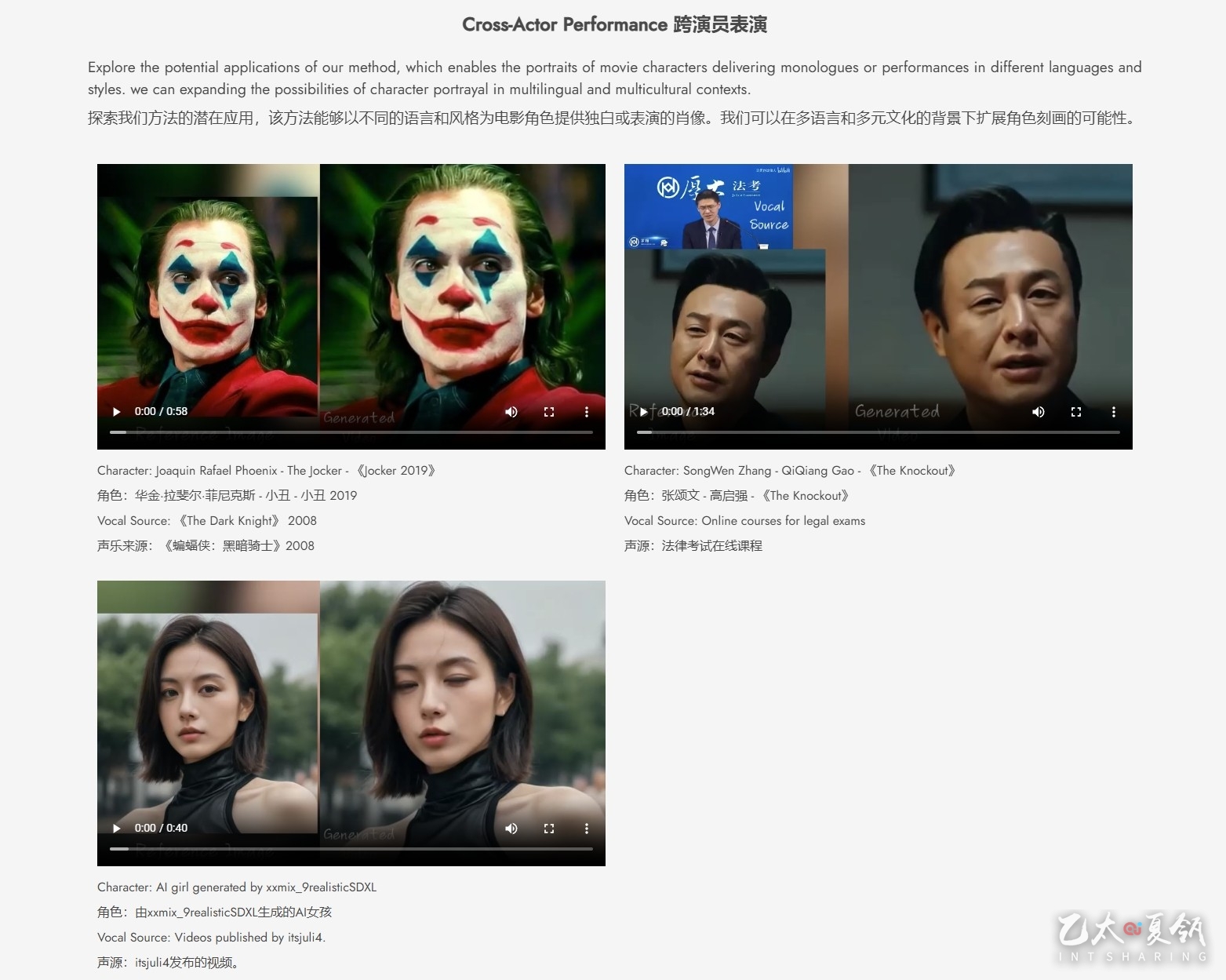
EMO一个富有表现力的音频驱动的纵向视频生成框架。输入单个参考图像和人声音频,例如说话和唱歌,我们的方法可以生成具有表现力的面部表情和各种头部姿势的人声头像视频,同时,我们可以根据输入视频的长度生成任何持续时间的视频。
EMO的核心亮点
- 音频直驱视频生成:EMO革新性地根据音频输入即时创作视频,摆脱了对预设视频或3D模型的依赖。
- 高保真表情模拟:精准捕捉并还原人类表情的微妙变化,包括微表情,与音频节奏完美同步的头部动作,尽显生动逼真。
- 流畅帧间过渡:保障视频帧间无缝衔接,杜绝扭曲与抖动,提升整体视觉享受。
- 身份一致性保持:FrameEncoding模块确保角色形象稳定如一,忠实于参考图像。
- 稳定控制体系:集成速度与面部区域控制器,加固生成流程,预防意外中断。
- 时长自由定制:灵活应对不同音频长度,激发无限创意可能。
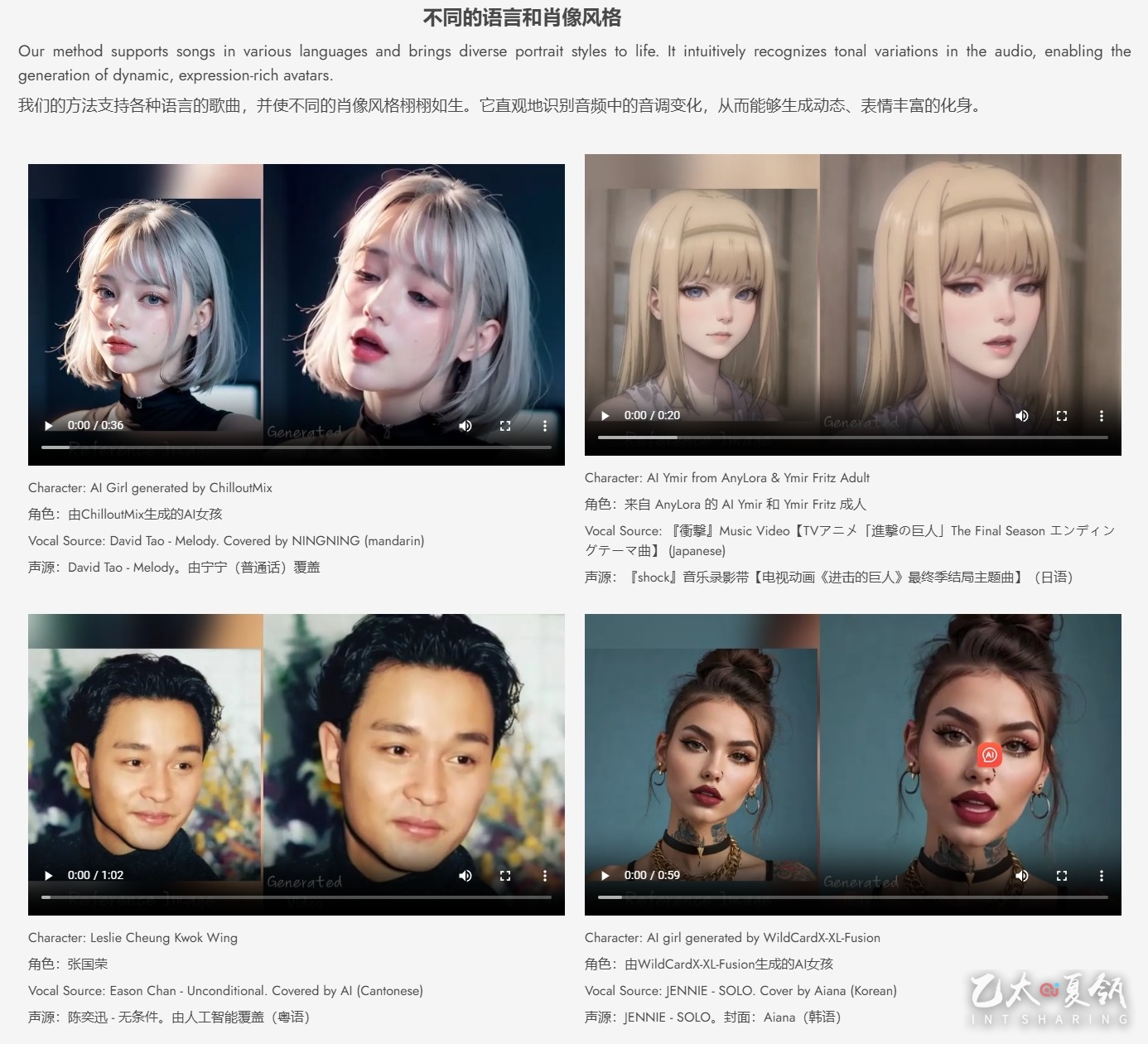
- 跨文化多风格兼容:训练数据横跨语言与风格界限,无论是中文、英文,还是现实、动漫、3D,均能轻松驾驭。
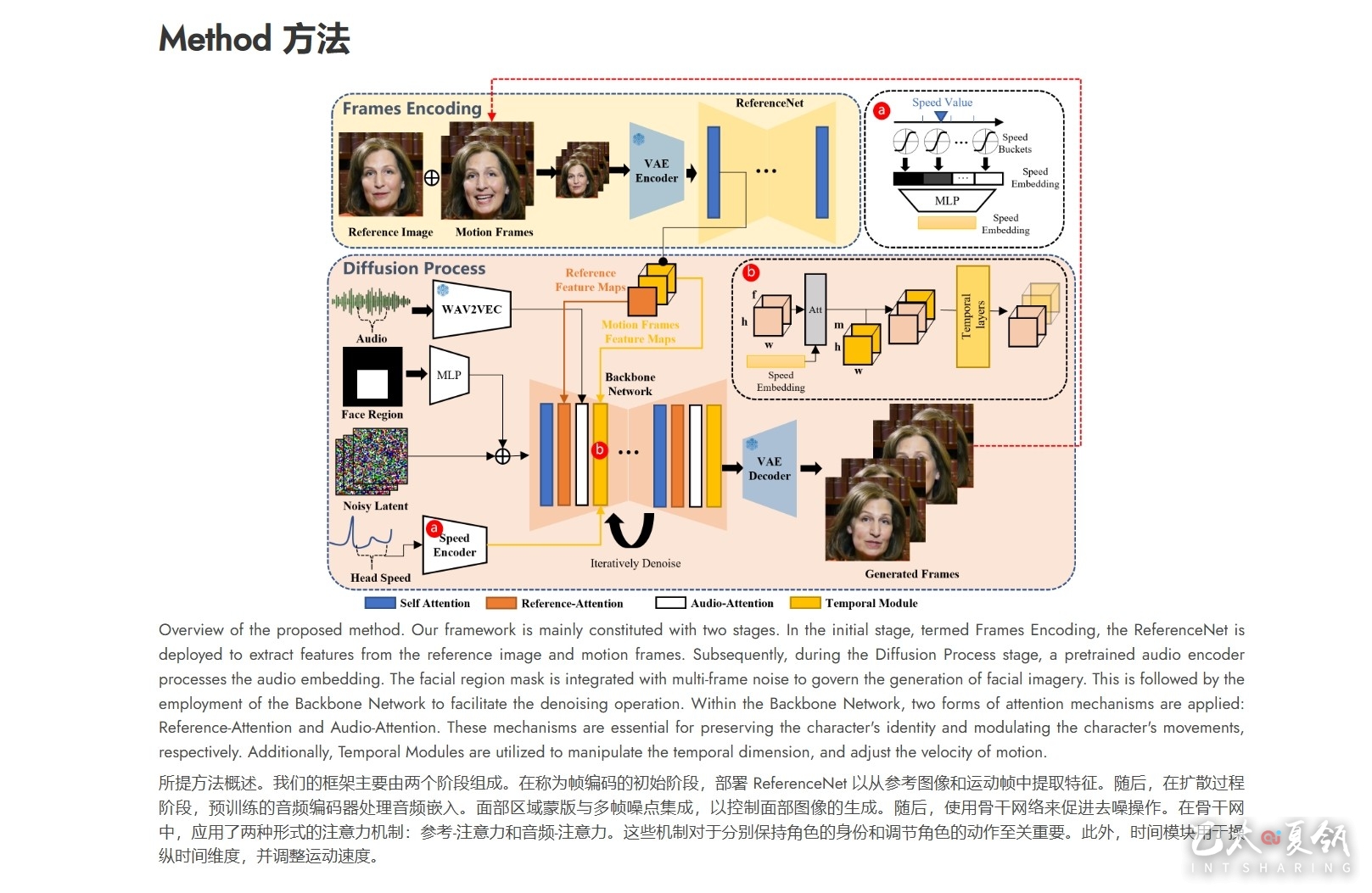
EMO的运作原理
- 输入筹备选定目标角色肖像作为参考,并导入音频文件,奠定视频创作基石。
- 特征抽取:ReferenceNet深度解析参考图像,提炼关键特征信息。
- 音频解析:预训练音频编码器精准提取音频特征,捕捉语音精髓,驱动表情与动作。
- 扩散去噪:主网络以噪声为起点,逐步去噪生成连续视频帧,Reference-Attention与Audio-Attention双管齐下,确保角色身份与动作协调。
- 时间调控:时间模块运用自注意力机制,精准把握视频动态,强化帧间连贯性。
- 定位与速度控制:面部定位器精准锁定面部区域,速度层灵活调整动作节奏,确保视频流畅自然。
- 分阶段训练:历经图像预训练、视频训练及速度层集成,层层递进,优化模型性能。
- 视频生成:在推理阶段,EMO使用DDIM采样算法生成视频片段。通过迭代去噪过程,最终生成与输入音频同步的肖像视频。
产品图库
视频课程

乙太夏瓴,集AI网址、资源、资讯于一体的导航网站,为您收集整理推荐国内外人工智能网址导航网站,文字写作,图片,音频,视频,代码等各种高效工具,让您遍览人工智能服务,先人一步,畅享未来!
 沪公网安备31010602007845号
沪公网安备31010602007845号
