致力打造国内好用的AI产品导航平台

开发者:2noise / ChatTTS
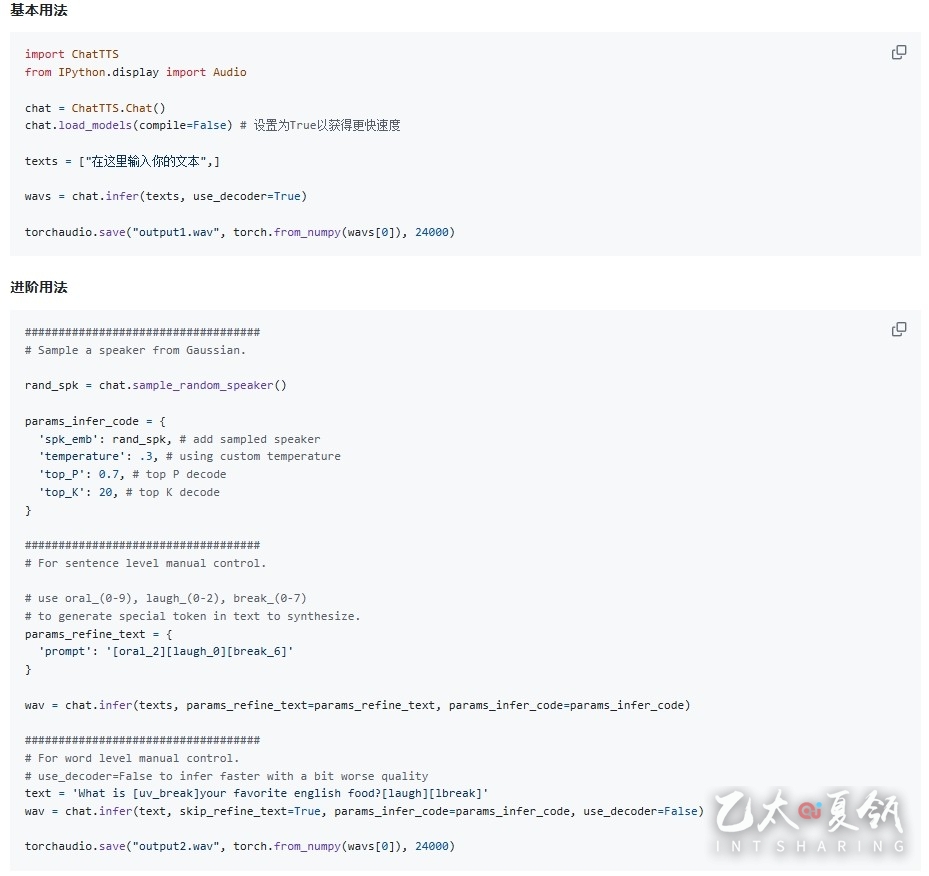
ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本.
亮点
1. 对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
2. 细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
3. 更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
常见问题
1. 连不上HuggingFace
请使用modelscope的版本. 并设置cache的位置:
2. chat.load_models(source='local', local_path='你的下载位置')
我要多少显存? Infer的速度是怎么样的?
对于30s的音频, 至少需要4G的显存. 对于4090, 1s生成约7个字所对应的音频. RTF约0.3.
3. 模型稳定性似乎不够好, 会出现其他说话人或音质很差的现象.
这是自回归模型通常都会出现的问题. 说话人可能会在中间变化, 可能会采样到音质非常差的结果, 这通常难以避免. 可以多采样几次来找到合适的结果.
4. 除了笑声还能控制什么吗? 还能控制其他情感吗?
在现在放出的模型版本中, 只有[laugh]和[uv_break], [lbreak]作为字级别的控制单元. 在未来的版本中我们可能会开源其他情感控制的版本.
产品图库


乙太夏瓴,集AI网址、资源、资讯于一体的导航网站,为您收集整理推荐国内外人工智能网址导航网站,文字写作,图片,音频,视频,代码等各种高效工具,让您遍览人工智能服务,先人一步,畅享未来!
 沪公网安备31010602007845号
沪公网安备31010602007845号
